
Microsoft hat ein KI-System namens SpreadsheetLLM entwickelt, das große Sprachmodelle nutzt, um Daten in Excel-Tabellen zu analysieren und zu interpretieren. Dieses Tool ermöglicht die Verarbeitung umfangreicher zweidimensionaler Gitter, flexible Layouts und verschiedene Formatierungsoptionen durch die Serialisierung von Daten und die Einbeziehung von Zelladressen, Werten und Formaten.
Ein Forschungspapier, das im Open-Access-Repository arXiv veröffentlicht wurde, erklärt, dass das Format von Tabellenkalkulationen eine erhebliche Herausforderung für große Sprachmodelle (LLMs) darstellt. Große Tabellenkalkulationen enthalten oft „zahlreiche homogene Zeilen oder Spalten“, die „minimale Beiträge zum Verständnis des Layouts und der Struktur leisten“ und die Analyse auch für Menschen schwierig machen.
Um diese Herausforderung zu meistern, serialisiert das LLM-gesteuerte Analysetool SpreadsheetLLM die Daten und integriert Zelladressen, Werte und Formate in einen Datenstrom. Dies führt jedoch zu einem weiteren Problem: den Token-Beschränkungen vieler LLMs, bei denen Token Zeichenketten oder Symbole sind.
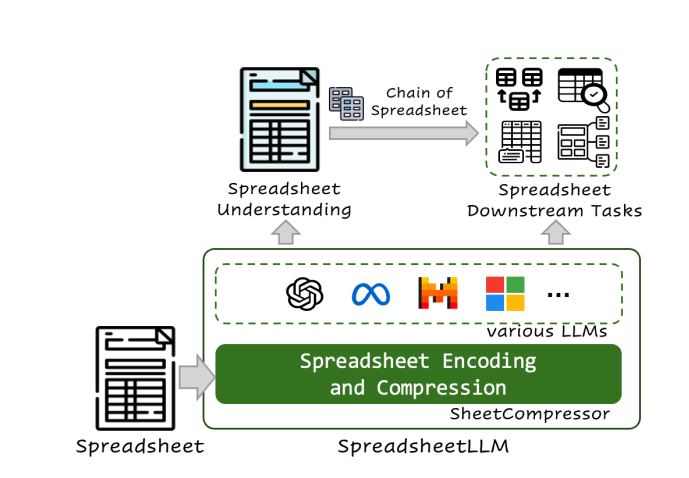
Um wiederum dieses Problem zu lösen, hat das Forschungsteam ein weiteres Framework namens SheetCompressor entwickelt, das aus mehreren Modulen besteht: Ein Modul analysiert die Tabellenstruktur und entfernt nicht-tabellarische Inhalte, ein weiteres überträgt die Daten in eine effizientere Darstellung, und das dritte aggregiert die Daten. Das erste Modul identifiziert „strukturelle Anker wie Tabellenränder“ und entfernt andere Zeilen und Spalten, um eine „Skelettversion“ der Tabelle zu erzeugen. Das zweite Modul verwirft das Zeilen- und Spaltenformat, indem es in ein invertiertes Indexformat in JSON konvertiert. Schließlich werden benachbarte Zellen mit denselben Zellformaten zusammengefasst.
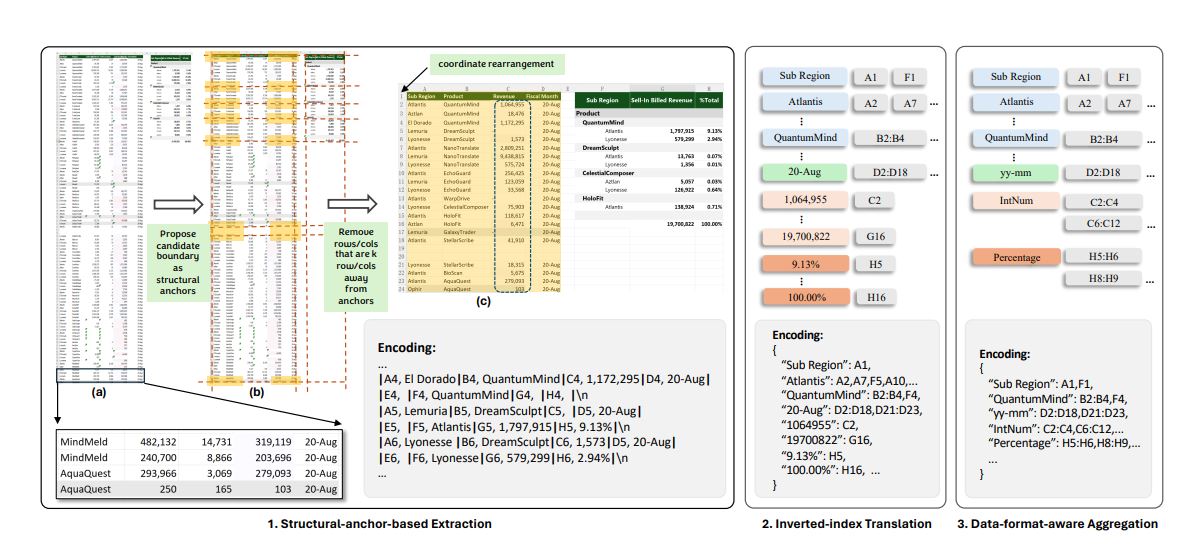
Das Ergebnis ist, dass eine Tabelle mit 576 Zeilen und 23 Spalten, die sonst 61.240 Token erfordert hätte, auf eine kompaktere Darstellung von nur 708 Token reduziert werden kann. Laut dem Papier reduziert SheetCompressor die Token-Nutzung zur Kodierung von Tabellen in der Regel um 96 Prozent. Dies könnte die Rechenkosten für die Verarbeitung von Tabellendaten erheblich senken und praktische Anwendungen auch für große Datensätze ermöglichen.
SpreadsheetLLM weist in seiner aktuellen Form einige Einschränkungen auf. Zum Beispiel werden Formatdetails wie die Hintergrundfarbe von Zellen ignoriert, da dies zu viele Token erfordern würde, obwohl diese manchmal zur Kodierung von Informationen verwendet werden (Viele Anwender verwenden die Hintergrundfarbe, um beispielweise den Status des Datensatzes zu beschreiben). SheetCompressor unterstützt derzeit auch keine semantische Komprimierungsmethode für Zellen, die natürliche Sprache enthalten, sodass Begriffe wie „China“ und „Amerika“ nicht unter einem einheitlichen Label wie „Land“ kategorisiert werden können.
Trotz dieser Einschränkungen hat SpreadsheetLLM in Tests traditionelle Ansätze um 25,6 % übertroffen, insbesondere im Kontextlernen mit GPT-4.
Dieses Analysetool kann die Datenverarbeitung in verschiedenen Branchen vereinfachen, indem es Aufgaben in der Buchhaltung und Datenanalyse löst. SpreadsheetLLM ermöglicht es nicht-technischen Benutzern, Tabellen-Daten mittels natürlicher Spracheingaben abzufragen und zu manipulieren.
Darüber hinaus kann das Tool die Arbeit von Fachleuten in den Bereichen Finanzen und Buchhaltung unterstützen, die große Datenmengen analysieren müssen. Beispielsweise ermöglicht das „Chain of Spreadsheets“-Modell (CoS) die Aufschlüsselung von Argumentationen in Tabellen in eine Pipeline aus „Entdeckung-Übereinstimmung-Argumentation“.
Besonders bemerkenswert ist die Fähigkeit des Modells, sowohl mit strukturierten als auch unstrukturierten Tabellendaten zu arbeiten. Laut den Forschern kann dieser Aspekt dazu beitragen, Halluzinationen in den von der KI generierten Ergebnissen zu reduzieren, indem die Tabelle als „Quelle der Wahrheit“ dient und so die Zuverlässigkeit der Analyse erhöht.
SpreadsheetLLM befindet sich derzeit zwar noch in der Forschungsphase, wir freuen uns jedoch bereits über die zukünftige Integration des Tools in unsere KI-Lösungen, um Excel-Tabellen noch besser für unsere Chatbots bzw. RAG (Retrieval Augmented Generation) aufzubereiten.
